Tech Beats-2

👉 Subscribe to my Substack to get the latest news and articles.
Machine Learns - Newsletter #2 #
Hi everyone, here is the 2nd issue. I was planing to publish every other week but things are just so fast and there is already more than enough content to share with you.
So yeah, it’s been a pretty packed week for me. Training more & more TTS models with upcoming languages to Coqui Studio API, implement Bark finetuning in 🐸TTS, dealing with weird bugs, in and out of meeting, being active on our Discord, reading more about LLMs… So it was a productive week for me. I hope yours has been just as fruitful.
So let’s dive in…
Bits&Pieces #
ChatGPT’s Political Bias in a Study #
🔗 Link
TLDR. A study conducted by researchers in computer and information science from the UK and Brazil has raised concerns about the objectivity of ChatGPT. According to the researchers, they have discovered significant political bias in ChatGPT’s responses, which tend to lean towards the left side of the political spectrum.
AMD: nearly half of enterprises not fully utilizing the benefits of AI. #
TLDR. In a recent survey conducted by AMD, insights have been revealed regarding the adoption of AI in enterprises. The survey involved 2,500 IT leaders from the US, UK, Germany, France, and Japan. The results showed that almost half of the enterprises are at risk of falling behind in AI.
China published Generative AI Governance Rules #
🔗 Link
TLDR. It’s essential for those running generative AI to make sure their services align with the fundamental principles of socialism, and steer clear of any content that promotes the overthrow of government power, separation, terrorism, or any activities that could weaken national unity and societal stability.
When utilizing data for model creation, it’s crucial to honor intellectual property rights and secure permission from individuals before including their personal details. Emphasis is also placed on enhancing the quality, genuineness, precision, impartiality, and variety of the data used for training.
In most situations, those who run generative AI services are required to secure licenses, introducing an additional level of regulatory supervision.
Research #
MeZO: Fine-Tuning Language Models with Just Forward Passes #
👉Code
This work proposes a memory-efficient zeroth-order optimizer (MeZO) for fine-tuning language models with just forward passes. The method significantly outperforms other techniques and achieves comparable performance to fine-tuning with backpropagation with up to 12× memory reduction.
What’s new: MeZO can train large models with the same memory footprint as inference.
How it works: The method uses a combination of random and deterministic perturbations to estimate the gradient of the loss function with respect to the model parameters. MeZO can effectively optimize non-differentiable objectives and is compatible with both full-parameter and parameter-efficient tuning techniques.

Key insights:
- MeZO is a memory-efficient zeroth-order optimizer that can adapt the classical zeroth-order stochastic gradient descent (ZO-SGD) algorithm and reduce its memory consumption to the same as inference.
- MeZO operates in-place on arbitrarily large models with almost no memory overhead.
- MeZO can effectively optimize non-differentiable objectives and is compatible with both full-parameter and parameter-efficient tuning techniques.
- MeZO can be combined with other gradient-based optimizers, including SGD with momentum or Adam, to further improve its performance.
- MeZO can be used to train large language models with a single GPU, making it a practical and scalable solution for finetuning large models.
Results: MeZO achieves state-of-the-art performance on several language modeling benchmarks, including the One Billion Word (OBW) and WikiText-103 datasets, while using significantly less memory than other methods.
Composable Function Preserving Expansions for Transformers #
👉Code
This paper proposes six composable transformations to incrementally increase the size of transformer-based neural networks while preserving functionality, allowing for more efficient training pipelines for larger and more powerful models. The proposed transformations are evaluated on several benchmark datasets and show improved performance compared to existing methods.
What’s new: This work contributes to the field of neural network architecture design by providing a new way to scale up transformer-based models without sacrificing functionality or requiring a complete restart of the training process.
How it works:The six transformations are:
- Depth-wise expansion: increases the number of layers in the model.
- Width-wise expansion: increases the number of neurons in each layer.
- Attention expansion: increases the number of attention heads in the model.
- Kernel expansion: increases the kernel size of the convolutional layers in the model.
- Channel expansion: increases the number of channels in the convolutional layers in the model.
- MLP expansion: increases the number of neurons in the multi-layer perceptron layers in the model.
Each transformation is designed to preserve the functionality of the model while expanding its capacity. The authors provide proof of exact function preservation under minimal initialization constraints for each transformation. The proposed approach allows for more efficient training pipelines for larger and more powerful models by progressively expanding the architecture throughout training. The effectiveness of the proposed approach is demonstrated on several benchmark datasets, where it shows improved performance compared to existing methods.
Key insights: Training transformers are expensive and with such incremental methods, models can be incrementally trained by adding additional components. It’d make the training process faster, cheaper, and much more energy efficient. Having said that, there are older methods proposed for convolutional networks and ResNets but they are not used in practice.
Results:The results show that the proposed approach outperforms existing methods in terms of accuracy and efficiency. On CIFAR-100, the proposed approach achieves a top-1 accuracy of 89.68%, which is higher than the state-of-the-art accuracy of 89.29%. On ImageNet, the proposed approach achieves a top-1 accuracy of 85.4%, which is higher than the state-of-the-art accuracy of 84.6%. The authors also show that the proposed approach is more efficient in terms of training time and memory usage compared to existing methods.
Consciousness in Artificial Intelligence #

TLDR. Can artificial intelligence (AI) systems be conscious? This paper explores this question by providing a rigorous and empirically grounded approach to assessing the consciousness of AI systems. The authors survey several prominent scientific theories of consciousness, derive “indicator properties” of consciousness, and use these indicators to assess several recent AI systems. The analysis suggests that no current AI systems are conscious, but there are no obvious technical barriers to building AI systems which satisfy these indicators.
Thinking: that consciousness is like a symphony, composed of numerous processes humming along in our brains. It’s as if our brains are nature’s version of a computer. Recent studies seem to back up this idea, hinting that our brains and consciousness might not be as unique as we once thought.
So, the question arises - could we build computers that mimic our brains? I believe there’s no wall standing in our way. But, just because we can, does it mean we should? That’s a question I’m still pondering.
If you are interested in the topic of consciousness in general, I strongly suggest this book with a very contrarian view point on general validity of consciousness theory.
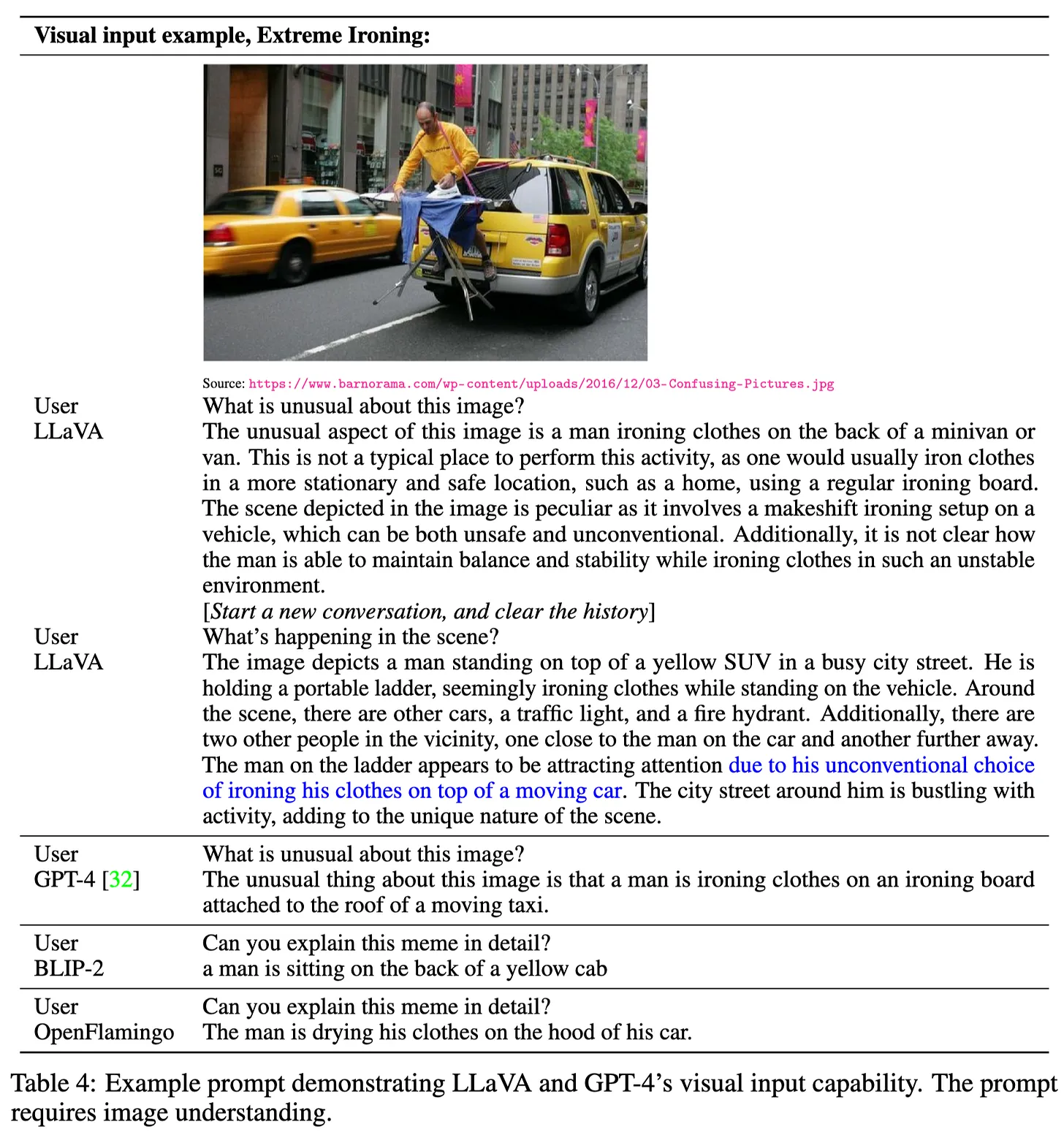
LLaVA - Visual Instruction Tuning #
👉 Github
🔬 Paper
👉 Demo
The paper introduces LLaVA, a Large Language and Vision Assistant, which is an end-to-end trained large multimodal model that is based on a vision encoder and a language decoder for general-purpose visual and language understanding.
What’s new:LLaVA is a new end-to-end trained large multimodal model that connects a vision encoder (CLIP) and language decoder (LLaMA) for general-purpose visual and language understanding. LLaVA proposes a GPT-4 assisted way for generating visual instruction data.
How it works:
- Language-only GPT-4 is used to generate visual-instruction data.
- The generated data is used to instruction tune LLaVA.
- LLaVA is capable of understanding both language and vision, and can generate responses to multimodal inputs.
- LLaVA is fine-tuned on Science QA, which is a task that requires answering questions based on scientific texts.
Results:LLaVA demonstrates impressive multimodal chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. The combination of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53% on Science QA
More Reads #
🔬 Brainformers: Trading Simplicity for Efficiency 🔬 Sparks of Large Audio Models: A Survey and Outlook 🔬 Are you copying my model 📝 Better Feedback Makes for Faster Review 📝 A Paradigm Shift in ML Validation: Evaluating Workflows, Not Tasks
Open Source #
Prompt2Model #
👉 Github
Prompt2Model is a system that takes a natural language task description (like the prompts used for LLMs such as ChatGPT) to train a small special-purpose model that is conducive for deployment.
Lilac #
👉 Github
Lilac is an open-source tool that enables AI practitioners to see and quantify their datasets.
Lilac allows users to:
- Browse datasets with unstructured data.
- Enrich unstructured fields with structured metadata using Lilac Signals, for instance near-duplicate and personal information detection. Structured metadata allows us to compute statistics, find problematic slices, and eventually measure changes over time.
- Create and refine Lilac Concepts which are customizable AI models that can be used to find and score text that matches a concept you may have in your mind.
- Download the results of the enrichment for downstream applications.
Pointers #
Simons Institute - Large Language Models and Transformers Workshop #
There are many interesting talks in this workshop. Here are some that I went through:
📹 Large Language Models Meet Copyright Law 📹 Panel Discussion 📹 Build Ecosystem, Not a Monolith 📹 Are LLMS the Beginning or End of NLP?
Ahead of AI - New Foundation Models #
🔗Post
Sebastian Raschka shares details about the latest LLMs including LLaMA models and GPT-4. Apperantly GPT-4 model details are leaked:
GPT-4 is a language model with approximately 1.8 trillion parameters across 120 layers, 10x larger than GPT-3. It uses a Mixture of Experts (MoE) model with 16 experts, each having about 111 billion parameters. Utilizing MoE allows for more efficient use of resources during inference, needing only about 280 billion parameters and 560 TFLOPs, compared to the 1.8 trillion parameters and 3,700 TFLOPs required for a purely dense model.
The model is trained on approximately 13 trillion tokens from various sources, including internet data, books, and research papers. To reduce training costs, OpenAI employs tensor and pipeline parallelism, and a large batch size of 60 million. The estimated training cost for GPT-4 is around $63 million.