Notes on Fine-tuning LLMs
👉 Subscribe to my Substack to get the latest news and articles.
I recently dedicated some time to watching the new course on fine-tuning large language models offered by Deep Learning AI. I took notes during my viewing and would like to share them here.
What is fine-tuning? #
Specializing LLMs, teaching a new skill instead of expanding its knowledge base. GPT4 is fine-tuned for Copilot to be a code assistant like a doctor is trained to be a dermatologist.
What does fine-tuning do? #
Learn the data rather than just accessing it.
- More consistent outputs
- Reduced hallucinations
- Specialize the model for a specific use case
Pros & Cons #
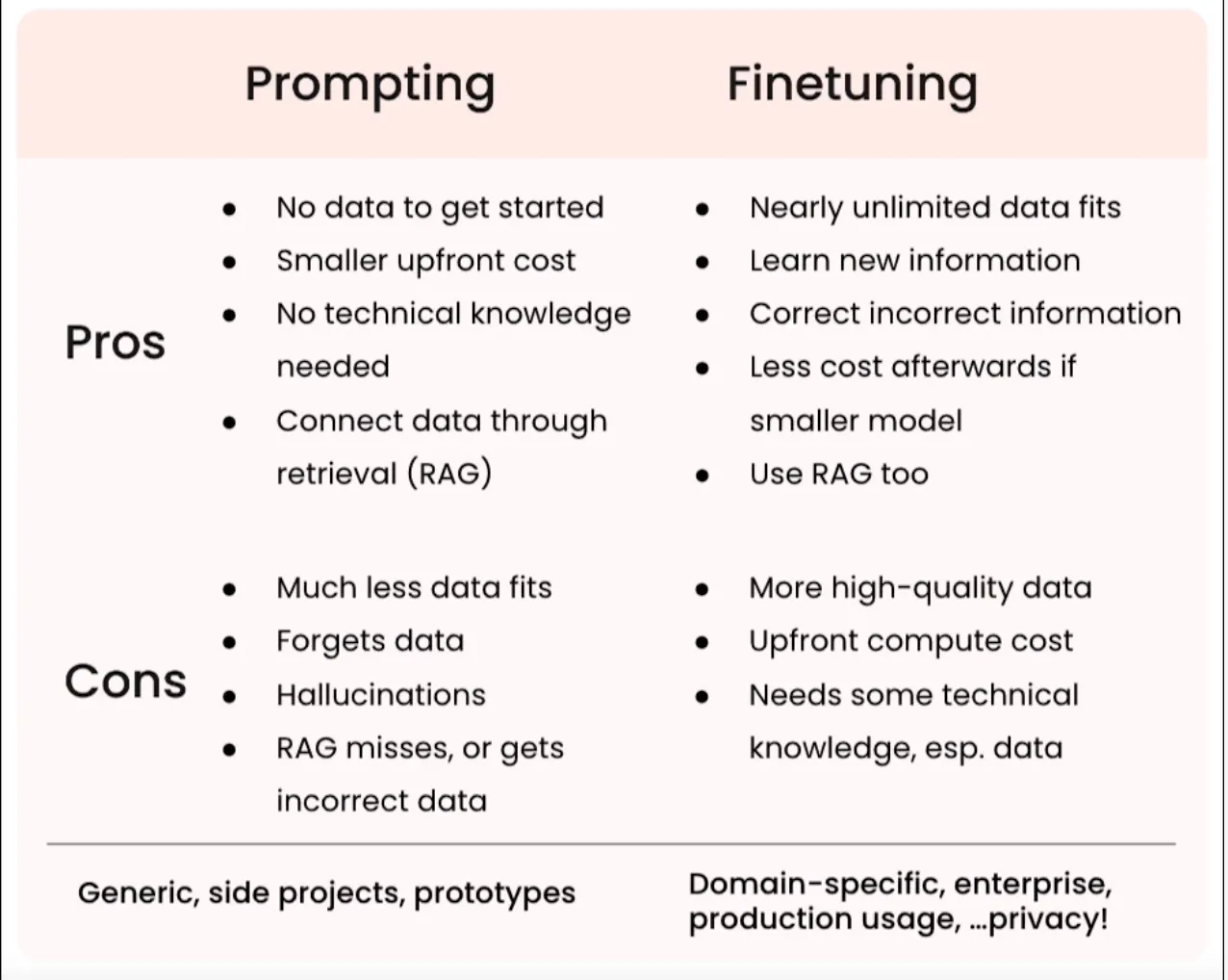
Benefits #
- Performance
- Reduced Hallucination: Reliable outputs tuned for the task.
- Consistency: Maintaining consistency by responding uniformly to the same input.
- Reduce unwanted information: Pre-trained models are lengthy and repetitive.
- Privacy
- Keep your data in-house: It is not OK to share your private data with a 3rd party every time in a prompt.
- Cost
- Lower cost per request: Prompting LLM services is expensive, especially when combined with vector search and contextual information.
- Control: For an enterprise, controlling technology must be adaptive and flexible enough when things change.
- Transparency: If you know what goes in, what comes out, and how things work, you can act more efficiently and make better decisions.
- Reliability
- Uptime: It is easier to meet the uptime requirements of a model you own than relying on an external service.
- Latency: Fine-tuned models are more efficient, and you can optimize them according to your needs.
- Moderation: You can easily feature your models’ flag or moderate inputs/outputs.
Pretraining #
- Trained by self-supervised learning → next word prediction
- Uses Unlabelled data → Wikipedia, Internet, etc.
- After learning, the model learns language & knowledge
- Expensive → $12m GPT3
- Generally, data is not public → ChatGPT, LLaMA
Finetuning #
- Can be trained by self-supervised learning
- Much less data
- Labeled data based on the target task
- Cheaper
- Easier to find data → In the organization, the Internet
- Data curation is more critical → “Your model is what your data is.”
Way to Fine-tuning #
- Check a pre-trained LLM performance on the task by prompt engineering.
- Find cases LLM performs ≤ OK.
- Get ~1000 samples for the task that shows examples better than the LLM.
- Fine-tune a small LLM on this data.
- Compare with the pre-trained LLM.
- Repeat until you get satisfying results.
Instruction Fine-tuning #
A specific way of fine-tuning that teaches models to follow instructions like a chatbot. It gave ChatGPT the ability to chat.
Data resources for instruction fine-tuning:s
- In-House: FAQs, Slack…
- Synthetic: Use a different LLM or templates to convert regular text to conversations. → Alpaca Model
- Example sample format (Alpaca):
- Instruction: Instruct the model to perform a specific task or behave in a certain way.
- Input: User input
- Response: Model’s answer based on the input and the instruction.
This is what the model tries to predict at fine-tuning.
sample = """
### Instructions:
{instruction}
### Input:
{Input}
### Response:
"""
Data Preparation #
“Your model is what your data is.”
Things to consider when creating a dataset:
- Quality
- Diversity
- Real is better than synthetic.
- More is better than less
- Less high quality is better than more low quality.
Preparation steps:
- Collect → Real or synthetic
- Format → Instruction Template
- Tokenization → Convert text to numbers
- Split → Train/Dev/Test
Training (Fun Part) #
Regarding regular LLM training, selecting the appropriate model to fine-tune is crucial. It is recommended to begin with around 1 billion parameter models for typical tasks, but in my personal experience, smaller models can be incredibly effective for specific tasks. Therefore, it is essential not to be swayed by the notion that bigger is always better in the LLM realm and to conduct research.
In addition, there are specific techniques, such as LoRA, that can enhance the efficiency of your training. You can incorporate one of these methods into your fine-tuning process if you have limited computing resources. By doing so, you can substantially reduce the amount of computing power needed without compromising performance.
Evaluation #
The evaluation process marks the start of the fine-tuning process rather than the conclusion. The objective is to continuously enhancing our model by conducting error analysis after each iteration. We assess our current model (at first, the base model), identifying errors and recurring issues. In the subsequent iteration, we determine if these issues have been resolved. If not, we incorporate additional targeted data to address these.
Common issues might be misspellings, long responses, repetitions, inconsistency, or hallucinations.
There are different formats of evaluation:
- Human evaluation (most reliable)
- Test suits → Rules for checking certain conditions. Stop words, exact match, consistency, similarity check by embeddings, etc.
- ELO comparison → A/B test between multiple models.
We can also use common benchmark datasets to compare our system:
- ARC → School questions
- HellaSwag → Common sense
- MMLU → Math
- TruthfulQA → Falsehood